One Input, Multiple Outputs - How You Can Leverage Your Work for Continuous Learning
As software developers we have a great benefit: our work offers us endless opportunities to learn new things. It is the jackpot when you believe in lifelong learning. However, we often do not make good use of those opportunities and end up with the feeling of not learning anything at all. I am convinced that this is due to how we persist our knowledge and the unfortunate idea that learning can't be fun.
Our daily routine
At a high-level of abstraction, we can description our work like this: take a task, read the requirements, do the complex work of developing a solution and deliver a piece of code that meets those requirements. We turn tasks into code and repeat this activity in an endless loop.

The big problem with this approach: If we come back 6 months later, it does not matter if we wrote this code or someone else. We cannot remember the details and often not even the reason for creating it in the first place. All the things we learned on the way from task to code is gone as well. We need to relearn everything, should we need to solve a similar problem again. That is frustrating and a waste of time. No wonder do we believe we don't make any progress – we spend all our time relearning things we once already understood. There must be a better way!
One input, multiple outputs
We need a way to persist the reasoning we do while we write the code. And we need to capture the knowledge we gained by solving that problem. Only when we no longer need to relearn the same things every 6 months are we able to leverage our work for continuous learning.
I had an epiphany as I attended the presentation "Hack Your Career" by Troy Hunt at last year's NDC. Troy talked about his little side project to learn Azure, Have I been pwned?, and how that resulted in TV interviews, contract work, blog posts and multiple courses for Pluralsight. Doing the work once and reuse the gained insights to create multiple outputs is highly effective. It is still a lot of work, but if you doing it this way, you get a lot more in return compared to the usual approach of learning just enough to create one single output.
What would happen if I could use his idea of leverage to my work and continuous learning? Would that not be a great help to keep the knowledge around and create all those artefacts that we should create anyway (like documentation and tests)?
Put it into action
Shortly after NDC I had a requirement for combining PDF files. To put the idea of "one input, multiple outputs" into action, I made a simple addition to my workflow: I started Notepad. A simple text editor where I copied the URLs of all the solutions I tried. Whenever I dismissed an approach, I wrote a few words next to it ("needs additional software", "License AGPL", "no active development"). To check if the approach worked, I wrote a minimalistic spike that combined two PDF files from our application into one single file. To check that it worked I had to open the PDF file manually, but for the spike I did not bother to write more code.
As I finally had a solution that worked, I started to write my code as I always do. So far, I had one input and a text file in addition to my code. That simple list of URLs and some words was quickly written while doing the work, but it will not be much use a few months from now.
To persist my reasoning and the steps I did to create my code, I wrote an Architecture Decision Record. This is the simplest way I know to document the problem you try to solve, your solution and the alternatives you dismissed along the way. Writing it right then meant I did not have to think long about what to write. The problem of combining PDF files, my approach and the solution was still fully in my head. The text file with the alternatives that didn't work out needed a bit of formatting and a few complete sentences to be useful. Nothing magical and none of it took much time.
Automated testing was the next step. Not only would that keep checking if everything works at the next update of the library I used, it could help to share my gained knowledge with my team as well. A simple check if the created file had the same checksum as a good PDF file I created before was all it took to verify the code. Writing that tiny bit of additional functionality and moving the code to a test method was done in a few minutes.
The hard part of figuring out how to test my production code was now already done. I could reuse the functionality of the other test, modify it a slight bit and create a new test that checked my production code. If both tests fail after an update, I know that the problem is in the library. If only my production code test fails, I know that our application has a problem. Whatever it will be, I do not need time to reproduce it and can start with addressing the problem.
All those parts where a great help to share my knowledge with my team. The minimalistic example in the library test explained the concept, the test for the production code documented the way we should use this method in our application.
This approach resulted in many more artefacts for the company and I could persist my knowledge in multiple ways – all with only one additional hour spend on the task.
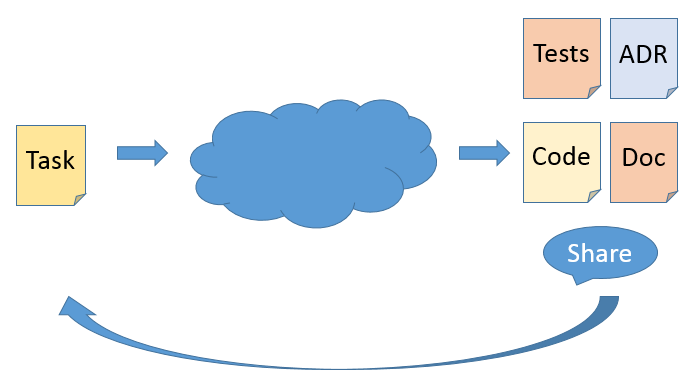
No need to learn it again?
Fast-forward 10 months where another application needs a similar functionality. I opened the ADR and did a quick check if the reasons for which I dismissed the alternative solutions where still valid. They were, so I did not need to go and spend time on them again. The library I used in the initial project released a new version with many changes. A quick update and a run of the automated tests gave me the confidence that we can safely update to the current release.
All I had to do now was to rewrite the code to match the slightly different requirements, what took me much less time than the first attempt. The documentation and examples where reduced to one test for the functionality in the second application and a reference to the documentation of the first one. That's it.
Instead of relearning how to combine PDF-files, I could leverage my documentation and delivered a solution in a short time. That is exactly what I hoped to achieve: being able to deliver quickly without the need to start from scratch.
Still being excited about that approach, I went on and wrote a blog post in my spare time. All I had to do was to create an even simpler example that does not need any of our company PDF files. From start with the new PDF files to the code and the post itself, I only had to spend 30 minutes of my own time. Again, I could leverage the work I did before, got an addition post that I can share and I did not need to spend hours figuring out a problem worth blogging about.
Who pays for that additional work?
One question comes up whenever I share this story: How can the company afford this? There is a lot of output, but you do not need to invest a lot of time - if you create it as part of your work. If you need to go back after weeks of doing other things, it would be a costly exercise. Unfortunately, that is how most documentation is written – long after the work is done. If you do it while you do the work, it takes a few additional minutes. As long as you use ADR or the arc42 template. The more complicated your documentation format, the more effort you need.
The same is true for testing. Writing the tests while you write the code is fast and does not increase the cost much. Do not wait with testing until the problems start showing up – that is the time when the cost explodes and you do not want to be in that spot.
So far, the additional time spend on those artefacts can be neglected. Their benefits not.
Conclusion
Try the idea of "one input, multiple outputs". Combining working and learning is not only effective, it helps you to get a good understanding of what lifelong learning means. As with every other skill, the more you learn new things, the easier it gets and the more you can achieve.