The Notable Difference in Dictionary Initialisation in C#
In C# we have two ways to initialise a dictionary. While both give us a dictionary in the end, there is a small but important difference when it comes to duplicated values. Let us explore the difference.
Collection initialiser
We can use the collection initialiser that is syntactic sugar for the add() method to create our dictionary:
If we would split the creation and the adding of values, we would write it like this:
Index initialiser
The second way to initialise a dictionary at its creation is the index initialiser that we can use since C# 6. This is syntactic sugar for setting values through the index of the key:
When we split the creation and the adding of the values into two parts, we would use this code:
Handling of duplicated keys
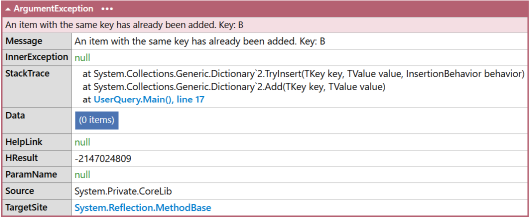
The interesting part happens when we have duplicated keys. The collection initialiser throws an exception:
This throws us an ArgumentException:
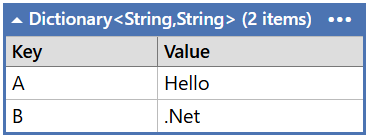
If we use the index initialiser, the second value overwrites the first value:
Conclusion
In C# we have two ways to create a dictionary and set values in the same operation. Both ways create identical dictionaries, what makes choosing one way over the other a matter of personal style. However, as soon as we have duplicated values, we may end up with an exception or a silent overwrite of values.
Whatever way we choose, we need to know that there is a difference. Otherwise, we end up with hard to track bugs and crashing applications.